README Files: The 50-Year-Old Pattern That's Perfect for the AI Age
README files have survived 50 years because they solve a fundamental problem: disorientation. What helped programmers navigate code in the 1970s now helps AI agents understand your projects in 2024. Discover the COMPASS system—a simple documentation pattern that works for humans and machines.

The Hidden Pattern: How a 1974 File Format became the Key to AI Agents
I. Introduction - The COMPASS Moment
All organizations run on documentation. Whether we call them SOPs, job aids, or simple notes, these artifacts are the only way we scale. They are how we ensure "Future You" remembers what "Yesterday You" built, and they are how we pass the torch to new team members without breaking stride.
If you are struggling to scale, the bottleneck is almost always process. Are your systems modular? Are they repeatable?
But recently, this problem has evolved. We are no longer just documenting for humans; we are documenting for AI Agents.
Everyone is talking about RAG (Retrieval-Augmented Generation) and autonomous systems, but we often ignore the prerequisite: Data Governance. We cannot build a global, intelligent system on top of broken processes. If humans within an organization don't understand the context of a project, a computer certainly won't either.
We need a method that solves both problems at once: a framework that orients humans while simultaneously providing structured context for AI. After years of experimentation, I’ve formalized a pattern that does exactly that.
And here is the best part: It isn't a fancy app. It isn't a complex SaaS tool. It is a simple text file that has been sitting under our noses for fifty years.
The thesis of this post is simple, but it changes everything about how we work with AI: README files are not just administrative chores; they are the bridge between human intent and machine execution.
II. The History Nobody Talks About
To understand the future of AI agents, we have to look back at a specific moment in the past—specifically, the mid-1970s at MIT.
It is widely accepted that the "README" concept was born around 1973-1974 on the MIT Incompatible Timesharing System (ITS). The earliest preserved instance was a file literally named -READ- -THIS-, created by Ron Lebel. It was a desperate plea for attention in a growing sea of data.
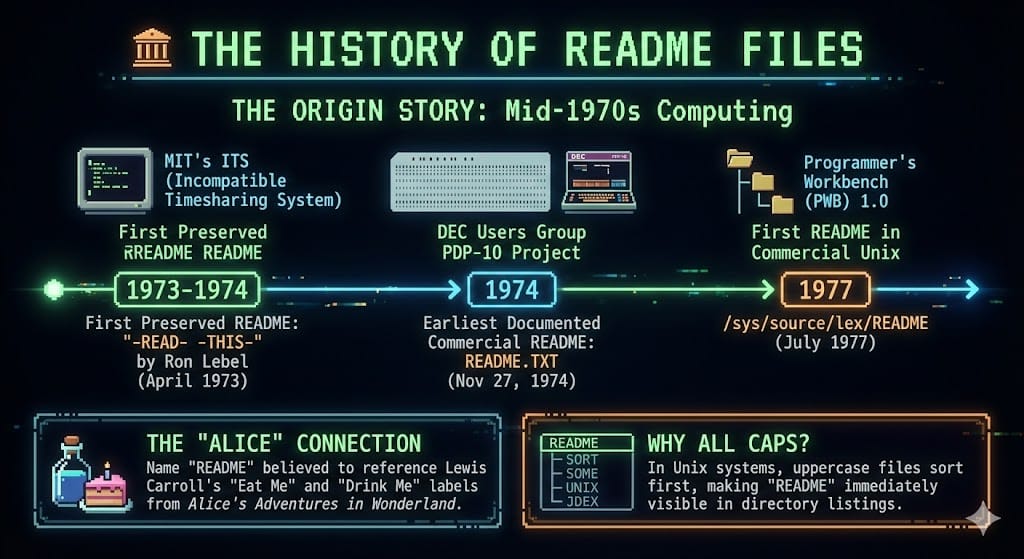
By November 1974, the README.TXT convention appeared in the DEC Users Group, and by 1977, it was standardized in commercial Unix.

But here is the fascinating part: Why is it in ALL CAPS?
It wasn't just to be loud. It was a clever hack for the limitations of the time. In Unix systems, file sorting is lexicographical (based on ASCII value). Uppercase letters have lower ASCII values than lowercase ones. By naming the file README, developers ensured it would always float to the very top of the directory listing, appearing before code.c or make.sh.
It is also rumored to be a nod to Lewis Carroll’s Alice in Wonderland, referencing the "EAT ME" and "DRINK ME" labels that guided Alice through a confusing world. Fifty years later, we are still Alice, and the README is still the potion that helps us make sense of the Wonderland of code.
III. The Scale: A 50-Year Survivor
Fast forward to today. The scale of this pattern is invisible but massive.
As of 2023, GitHub reported over 420 million active repositories, up from 200 million in 2022. That means there are hundreds of millions of README files currently in existence. It is arguably the most successful file naming convention in the history of computing.
Tom Preston-Werner, co-founder of GitHub, championed the concept of "Readme Driven Development" (RDD)—the idea that you should write the README before you write a single line of code.
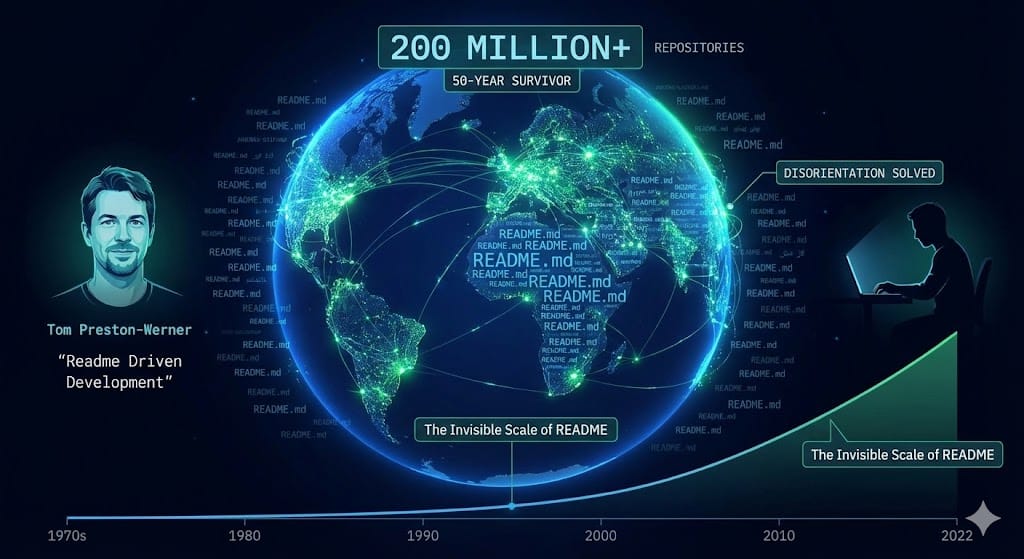
Why has this file survived for half a century? Because it solves a fundamental human problem: Disorientation.
IV. Anatomy of a Great README
If we accept that the README is the most important file in your project, what makes a good one? Based on consensus from the open-source community and GNU Coding Standards, here are the essentials.
The Core Components
Every README needs these sections to function:
- Project Title & Description: What is this, and in 2-3 sentences, what does it do?
- Installation: Step-by-step setup. (Even for yourself—you will forget).
- Usage: Examples of how to actually use the tool. Show, don't just tell.
- Context: Why does this exist? (The "Why" is often more important than the "How").

Do's and Don'ts
A README is only useful if it is readable. Here is how to keep it clean (and mobile-friendly):
✅ The Green Flags (Do This)
- Use Markdown: Headers, bold text, and lists make the document skimmable.
- Include Visuals: Screenshots, GIFs, or ASCII art help users orient quickly.
- Update Often: An outdated README is worse than no README.
❌ The Red Flags (Avoid This)
- Wall of Text: Do not write a novel without paragraph breaks.
- Assume Knowledge: Don't skip installation steps assuming the user "just knows."
- Be Vague: "Project files" is not a valid description.
V. The AI Revolution: Why This Matters NOW
This is where the COMPASS system comes into play. This is the pivot.
For 50 years, the README solved a Human Problem:
Humans needed quick orientation to software in resource-constrained environments.
Today, the README solves an AI Problem:
AI Agents need structured context to function effectively.
When you feed a codebase to an LLM (like Gemini, Claude, or GPT), the model has to scan thousands of lines of code to understand the intent. It is computationally expensive and prone to hallucination.
However, if you have a robust README.md, you are effectively providing the AI with a System Prompt for your directory.
- The Old Way: You manually explain your project to the AI every time you start a new chat.
- The COMPASS Way: You point the AI to the README. It instantly understands the structure, the intent, the tech stack, and the goals.
The README is no longer just documentation; it is the context layer for the age of AI.
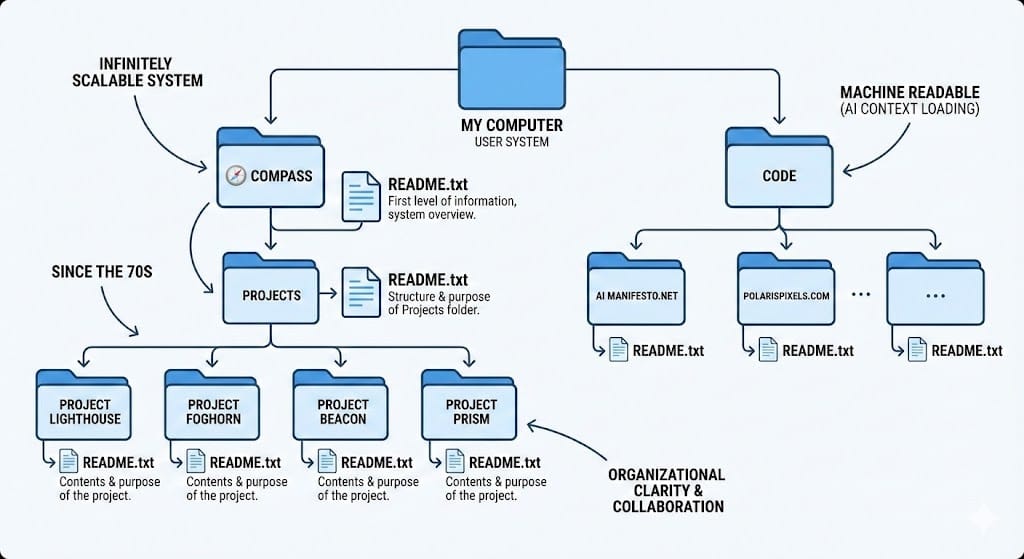
VI. Practical Implementation: The 3-Level Protocol
The beauty of this system is that it doesn’t require new software. It works on a Mac, a PC, or a Linux server. It works for Python scripts, and it works for marketing campaigns.
Here is how I structure my COMPASS system, organized into three levels of resolution.
Level 1: The Master Index (The Map)
This is the high-level view. I currently maintain a simple document listing my 14 active projects. This acts as a "Map" for both me and my AI agents.
Each entry contains two things:
- The Short Code: A one-word identifier (e.g.,
Foghorn,Prism,Beacon). This matches the actual folder name on my hard drive. - The Brief: A one-sentence description of what the project is.
Why this matters for AI: When I ask an AI agent to "Help me with the new video project," it can scan Level 1, identify the project Prism, and know exactly which folder to look in.
Level 2: The Project Root (The Context)
Once you navigate into a specific folder (e.g., /Code/Prism or /Projects/Foghorn), you find the anchor of the system: The README.
This is the "Landing Page" for the project. Whether it is a coding project or a writing project, this file contains the Goal, the Status, and the Quick Start guide. This ensures that every time I open a folder—or every time an AI agent indexes it—there is zero ambiguity about what is inside.
Level 3: Specialized Breakouts (The Details)
Sometimes, a single README isn't enough. If Project Prism has a complex deployment procedure, that gets its own standalone document (e.g., deployment_guide.md). This prevents the main README from becoming cluttered while still preserving the details.

README.md in Project_Foghorn to get the necessary context without manual explanation.The Result: Machine-Readable Clarity
By sticking to this structure, I have created a file system that is deterministic.
- Non-Code Projects live in my
Projectsfolder. - Code Projects live in my
Codefolder. - Every folder has a README.
This creates a "predictable path" for AI agents (and Humans). They don't have to guess where the context is hidden. It's always in the README.
VII. Conclusion - Building in Public
There is a meta-layer to all of this. You are currently reading a blog post about a documentation system, which was written using the very system it describes.
The COMPASS system isn't just a diagram; it's a blueprint for sanity in a digital world that is getting noisier by the second.
I am building this in public because I believe we are all facing the same problem: Data Overload. We are hoarding files but losing context.
I invite you to steal this system.
- Create a Master List of your active projects.
- Give each one a Short Code.
- Put a README in every single folder.
It’s a small habit that pays compound interest. It helped me navigate the last 50 years of computing history, and it’s how I’m preparing for the next 50 years of AI.
For more on building AI-ready systems, check out my other posts on systems thinking and AI implementation.

Comments ()